You’re still seeing SPF-related DMARC failures when sending emails
In my case, those failures were caused because I was sending email from a different identity that uses the same domain.
For example, I had ‘example.com’ set up as a verified identity in SES allowing me to send email from any address at that domain, and I configured a sender identity ‘contact@example.com’ to be used by my application to send emails so that I could construct an ARN for use with Cognito or similar.
What isn’t necessarily obvious is that you need to enable the custom MAIL FROM setting for the sender identity, and not just for the domain identity that you’ve configured assuming you have multiple. AWS SES does not fall back to the configuration for the domain identity and you have to individually enable custom MAIL FROM for each sender identity – even if the configuration is identical.
So in my case, the fix was:
Edit the Custom MAIL FROM setting for contact@example.com
Enable it to use mail.example.com (which was already configured)
I recently had a requirement to securely access a couple of Google Cloud APIs as a service account user, where those calls were being made from a Fargate task running on AWS. The until-relatively-recently way to do this was:
Create a service account in the Google Cloud developer console
Assign it whatever permissions it needs
Create a ‘key’ for the account – in essence a long-lived private key used to authenticate as that service account
Use that key in your Cloud SDK calls from your AWS Fargate instance
This isn’t ideal, because of that long-lived credential in the form of the ‘key’ – it can’t be scoped to require a particular originator and while you can revoke it from the developer console, if the credential leaks you’ve got an infinitely long-lived token usable from anywhere – you’d need to know it had leaked to prevent its use.
Google’s Workload Identity Federation is the new hotness in that regard, and is supported by almost all of the client libraries now. Not the .NET one though, irritatingly, which is why this post from Johannes Passing is, if you need to do this from .NET-land, absolutely the guide to go to.
The new approach is more in line with modern authentication standards and uses federation between AWS and Google Cloud to support generating short-lived, scoped credentials that are used for the actual work and no secrets needing to be shared between the two environments.
The docs are broadly excellent, but I was pleased at how clever the AWS <-> Google Cloud integration is given that there isn’t any AWS-supported explicit identity federation actually happening, in the sense of established protocols (like OIDC, which both clouds support in some fashion).
How it works
On the Google Cloud side, you set up a ‘Workload identity pool’ – in essence a collection of external identities that can be given some access to Google Cloud services. Aside from some basic metadata, a pool has one or more ‘providers’ associated with it. A provider represents an external source of identities, for our example here AWS.
A provider can be parameterised:
Mappings translate between the incoming assertions from the provider and those of Google Cloud’s IAM system
Conditions restrict the identities that can use the identity pool via a rich syntax
You can also attach Google service accounts to the pool, allowing those accounts to be impersonated by identities in the pool. You can restrict access to a given service account via conditions, in a very similar way to restricting access to the pool itself.
To get an access token on behalf of the service account, a few things are happening (in the background for most client libraries, and explicitly in the .NET case).
Authenticating with the pool
In AWS land, we authenticate with the Google pool by asking it to exchange a provider-issued token for one that Google’s STS will recognise. For AWS, the required token is (modulo some encoding and formatting) a signed ‘GetCallerIdentity’ request that you might yourself send to the AWS STS.
Our calling code in AWS-land doesn’t finish the call – we don’t need to. Instead, we sign a request and then pass that signed request to Google which makes the call itself. We include in the request (and the fields that are signed over) the URI of the ‘target resource’ on the Google side – the identity pool that we want to authenticate to.
The response from AWS to Google’s call to the STS will include the ARN of the identity for whom credentials on the AWS side are available. If you’re running in ECS or EC2, these will represent the IAM role of the executing task.
We need share nothing secret with Google to do this, and we can’t fake an identity on AWS that we don’t have access to.
The ARN of the identity returned in the response to GetCallerIdentity includes the AWS account ID and the name of any assumed role – the only thing we could ship to Google is proof of an identity that we already have access to on the AWS side.
The Google workflow identity pool identifier is signed over in the GetCallerIdentity request, so the token we send to Google can only be used for that specific user pool (and Google can verify that, again with no secrets involved). This means we can’t accidentally ship a token to the wrong pool on the Google side.
The signature can be verified without access to any secret information by just making the request to the AWS STS. If the signature is valid, Google will receive an identity ARN, and if the payload has been tampered with or is otherwise invalid then the request will fail.
None of the above requires any cooperation between AWS and Google cloud, save for AWS not changing ARN formats and breaking identity pool conditions and mappings.
What happens next?
All being well, the Google STS returns to us a temporary access token that we can then use to generate a real, scoped access token to use with Google APIs. That token can be nice and short lived, restricting the window over which it can be abused should it be leaked.
What about for long-lived processes?
Our tokens can expire in a couple of directions:
Our AWS credentials can and will expire and get rolled over automatically by AWS (when not using explicit access key IDs and just using the profile we’re assuming from the execution role of the environment)
Our short-lived Google service account credential can expire
Both are fine and handled the same way – re-run the whole process. Signing a new GetCallerIdentity request is quick, trivial and happens locally on the source machine. And Google just has to make one API call to establish that we’re still who we said we were and offer up a temporary token to exchange for a service account identity.
When you create a Route 53 public hosted zone, four DNS nameservers are allocated to the zone. You then use these name servers with your domain registrar to delegate DNS resolution to Route 53 for your domain.
However: each time you re-create a Route 53 hosted zone, the DNS nameservers allocated will change. If you’re using CloudFormation to manage your public hosted zone this means a destroy and recreate breaks your domain’s name resolution until you manually update your registrar’s records with the new combination of nameservers.
Route 53 reusable delegation sets are stable collections of Route 53 nameservers that you can create once and then reference when creating a public hosted zone. That zone will now have a fixed set of nameservers, regardless of how often it’s destroyed and recreated.
Shame it’s not in CloudFormation
There’s a problem though. You can only create route 53 reusable delegation sets using the AWS CLI or the AWS API. There’s no CloudFormation resource that represents it (yet).
Worse, you can’t even reference an existing, manually-created delegation set using CloudFormation. Again, you can only do it by creating your public hosted zone using the CLI or API.
So how can we achieve our goal of defining a Route 53 public hosted zone in code, while still letting it reference a delegation set ID?
Enter CDK and AwsCustomResource
CDK generates CloudFormation templates from code. I tend to use TypeScript when building CDK stacks. On the face of it, CDK doesn’t help us as if we can’t do something by hand-cranking some CloudFormation, surely CDK can’t do it either.
Not so. CDK also exposes the AwsCustomResource construct that lets us call arbitrary AWS APIs as part of a CloudFormation deployment. It does this via some dynamic creation of Lambdas and other trickery. The upshot is that if it’s in the JavaScript SDK, you can call it as part of a CDK stack with very little extra work.
Let’s assume that we have an existing delegation set whose ID we know, and we want to create a public hosted zone linked to that delegation set. Wouldn’t it be great to be able to write something like:
new PublicHostedZoneWithReusableDelegationSet(this, "PublicHostedZone", {
zoneName: `whatever.example.com`,
delegationSetId: "N05_more_alphanum_here_K"
// Probably pulled from CI/CD
});
Well we can! Again in TypeScript, and you’ll need to reference the @aws-cdk/custom-resources package:
Note: thanks to Hugh Evans for patching a bug in this where the CallerReference wasn’t adequately unique to support a destroy and re-deploy
How does it work?
The tricky bits of the process are handled entirely by CDK – all we’re doing is telling CDK that when we create a ‘PublicHostedZoneWithReusableDelegationSet‘ construct, we want it to call the Route53::createHostedZone API endpoint and supply the given DelegationSetId.
On creation we track the returned Id of the new hosted zone (which will be of the form ‘/hostedzone/the-hosted-zone-id’).
The above resource doesn’t support updates properly, but you can extend it as you wish. And the interface for PublicHostedZoneWithReusableDelegationSet is exactly the same as the standard PublicHostedZone, just with an extra property to supply the DelegationSetId – you can just drop in the new type for the old when needed.
When you want to reference the newly created PublicHostedZone, there’s the asPublicHostedZone method which you can use in downstream constructs.
I found a Stack Overflow question with no answers that seemed like it should be straightforward – how can you traverse a tree-like structure in depth-first order. The problem had a couple of features:
Each node had an order property that described the order in which sibling nodes should be traversed
Each node was connected to its parent via a PART_OF relationship
A depth-first traversal of a tree is pretty easy to understand.
Whenever we find a node with children, we choose the first and explore as deep into the tree as we can until we can’t go any further. Next we step up one level and choose the next node we haven’t explored yet and go as deep as we can on that one until we’ve traversed the graph.
Neo4j supports a depth-first traversal of a graph by way of the algo.dfs.stream function.
Given some tree-like graph where nodes of label ‘Node’ are linked by relationships of type :PART_OF:
We can see which nodes are visited by Neo4j’s DFS algorithm:
MATCH (startNode: Node { name: 'N1' } )
CALL algo.dfs.stream('Node', 'PART_OF', 'BOTH', id(startNode))
YIELD nodeIds
UNWIND nodeIds as nodeId
WITH algo.asNode(nodeId) as n
RETURN n
The outupt here will vary – possibly even between runs. While we’ll always see a valid depth-first traversal of the nodes in the tree, there’s no guarantee that we’ll always see nodes visited in the same order. That’s because we’ve not told Neo4j in what order to traverse sibling nodes.
If you need control over the order siblings are expanded, you should use application code to write the DFS yourself.
But: given some constraints and accepting some caveats…
That’s there’s only one relationship that links nodes in the tree
That sibling nodes are sortable by some numeric property – here ‘order`, which is mandatory
There are not more than 1,000,000 sibling nodes for any given parent
Sibling nodes all have a distinct order property value
That this will perform like a dog on large graphs – potentially not completing, given it has some N^2 characteristics…
…you can do this in pure Cypher. Here’s one approach, which we’ll then break down
to see how it works:
MATCH (root: Node { name: 'N1' }), pathFromRoot=shortestPath((root)<-[:PART_OF*]-(leaf: Node)) WHERE NOT ()-[:PART_OF]->(leaf)
WITH nodes(pathFromRoot) AS pathFromRootNodes
WITH pathFromRootNodes, reduce(pathString = "", pathElement IN pathFromRootNodes | pathString + '/' + right("00000" + toString(pathElement.order), 6)) AS orderPathString ORDER BY orderPathString
WITH reduce(concatPaths = [], p IN collect(pathFromRootNodes) | concatPaths + p) AS allPaths
WITH reduce(distinctNodes = [], n IN allPaths | CASE WHEN n IN distinctNodes THEN distinctNodes ELSE distinctNodes + n end) AS traversalOrder
RETURN [x in traversalOrder | x.name]
Finding the deepest traversals
Given some root node, we can find a list of traversals to each leaf node using shortestPath. A leaf node is a node with no children of its own, and shortestPath (so long as we’re looking at a tree) will tell us the series of hops that get us from that leaf back to the root.
Sorting the paths
We’re trying to figure out the order in which these paths would be traversed, then extract the nodes from those paths to find the order in which nodes would be visited.
The magic is happening in this line:
WITH pathFromRootNodes, reduce(pathString = "", pathElement IN pathFromRootNodes | pathString + '/' + right("00000" + toString(pathElement.order), 6)) AS orderPathString ORDER BY orderPathString
The reduce is, given a node from root to leaf, building up a string that combines the order property of each node in the path with forward-slashes to separate them. This is much like folder paths in a file system. To make this work, we need each segment of the path to be the same length – therefore we pad out the order property with zeroes to six digits, to get paths like:
These strings now naturally sort in a way that gives us a depth-first traversal of a graph using our order property. If we order by this path string we’ll get the order in which leaf nodes are visited, and the path that took us to them.
Deduplicating nodes
The new problem is extracting the traversal from these paths. Since each path is a complete route from the root node to the leaf node, the same intermediate nodes will appear multiple times across all those paths.
We need a way to look at each of those ordered paths and collect only new nodes – nodes we haven’t seen before – and return them. As we do this we’ll be building up the node traversal order that matches a depth-first search.
WITH reduce(concatPaths = [], p IN collect(pathFromRootNodes) | concatPaths + p) AS allPaths
WITH reduce(distinctNodes = [], n IN allPaths | CASE WHEN n IN distinctNodes THEN distinctNodes ELSE distinctNodes + n end) AS traversalOrder
First we collect all the paths (which are now sorted by our traversal ordering) into one big list. The same nodes are going to appear more than once for the reasons above, so we need to remove them.
We can’t just DISTINCT the nodes, because there’s no guarantee that the ordering that we’ve worked hard to create will be maintained.
Instead, we use another reduce and iterate over the list of nodes, only adding a node to our list if we haven’t seen it before. Since the list is ordered, we take only the first of each duplicate and ignore the rest. Our CASE statement is doing the heavy lifting here:
WITH reduce(distinctNodes = [], n IN allPaths | CASE WHEN n IN distinctNodes THEN distinctNodes ELSE distinctNodes + n end) AS traversalOrder
Equivalently:
Create a variable called distinctNodes and set it to be an empty list
For each node n in our flattened list of nodes in each path from root to each leaf:
If we’ve seen n before (if it’s in our ‘distinctNodes’ list) then set distinctNodes = distinctNodes – effectively a no-op
If we haven’t seen n before, set distinctNodes = distinctNodes + n – adding it to the list
This is a horrendously inefficient operation – for a very broad, shallow tree (one where each node has many branches) we’ll be doing on the order of n^2 operations. Still, it’s only for fun.
We’re done! From our original graph, we’re expecting a traversal order of:
N1, N2, N4, N5, N6, N3, N7
And our query?
["N1","N2","N4","N5","N6","N3","N7"]
Another for the annals of ‘Just because you can, doesn’t mean you should’.
If you come from a SQL background, you would probably not expect aliasing a column or table to have a measurable impact on performance.
Not quite so in Cypher.
Let’s build a sample graph of one million nodes (Neo4j Desktop running 3.5.13 Enterprise, 16GB max heap, 8GB initial heap):
CREATE CONSTRAINT ON (n: Node) ASSERT n.id IS UNIQUE
FOREACH (r in range(1, 1000000) | MERGE (n: Node { id: r }))
RETURN 1
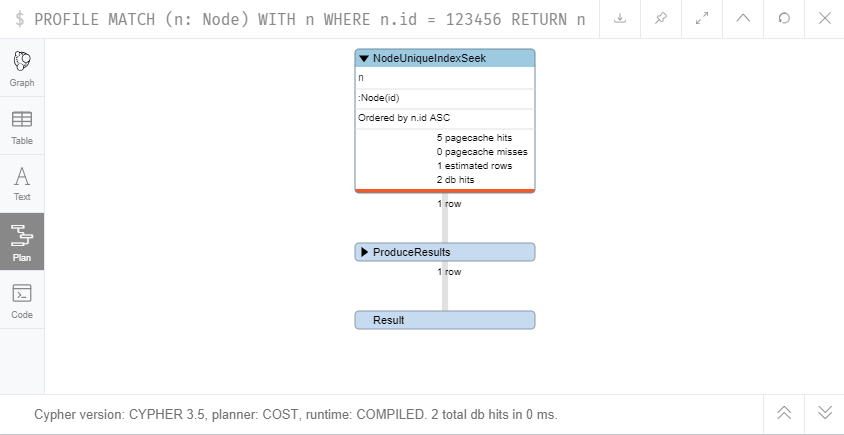
Profiling a basic query on :Node(id) shows that we’re hitting the index just fine and this query runs quick as you like:
PROFILE MATCH (n: Node)
WHERE n.id = 123456
RETURN n
// 2 total db hits in 1 ms
If we introduce a WITH into the mix, before the WHERE clause – what would you expect? Let’s add a redundant one and see:
PROFILE MATCH (n: Node)
WITH n
WHERE n.id = 123456
RETURN n
// 2 total db hits in 0 ms
No difference, nor would you expect one – the WHERE clause obviously relates to an indexed property, irrespective of the WITH.
What then if we give the WITH an alias?
PROFILE MATCH (n: Node)
WITH n as nAlias
WHERE nAlias.id = 123456
RETURN nAlias
// 2000001 total db hits in 422 ms
Even though to your eye that’s the same query, the optimiser in Neo4j has lost track of the indexability of the query, and we’re down to a NodeByLabelScan of 1,000,000 nodes.
I’d argue this is an optimiser bug, and have raised a bug for it (though it’s likely super low priority, and I suspect the sort of thing that sounds easier to fix than it actually is).
Still, it’s easy to fall into this sort of trap when refactoring big queries. For clarity and safety, if you’re going to try to hit an index do it in a WHERE clause attached directly to your MATCH. And regardless, re-profile your queries after refactoring them as part of your validation.
I answered a Stack Overflow question the other day about why two queries performed very differently. One involved a chain of OPTIONAL MATCHes, the other a single OPTIONAL MATCH with portions of a pattern separated by commas.
There’s a difference between the two that will almost certainly give you different results.
Patterns in Neo4j
A pattern is a description of a structure in a graph we’re trying to match. Patterns can assign nodes and relationships to variables we use in subsequent processing. They express both the nodes we’re looking for and how they must be related. They’re fundamental to a graph query – and the docs aren’t super-clear on how patterns with commas work.
A pattern might be something like ‘Actors connected to Movies via an ‘ACTED_IN’ relationship’.
Patterns with commas
A MATCH statement where the pattern contains a comma is still one MATCH statement. Every component of the pattern must be satisfied for the MATCH to return anything.
Let’s say we’re using the Movies database, and we want to find the directors of movies Tom Cruise has starred in.
One way is to assign a variable to the Movie node, and use commas:
MATCH (tom: Person { name: 'Tom Hanks' })-[:ACTED_IN]->(m: Movie), (director: Person)-[:DIRECTED]->(m)
RETURN DISTINCT director.name
Even though it might look as though we’re specifying two patterns we’re not: it’s all part of the same pattern. If Neo4j can’t satisfy any portion of the MATCH, it’ll return nothing.
Alternatively we could also use two MATCH statements one after the other:
MATCH (tom: Person { name: 'Tom Hanks' })-[:ACTED_IN]->(m: Movie)
MATCH (m)<-[:DIRECTED]-(director: Person)
RETURN DISTINCT director.name
In this example there’s no difference between the two queries – they’re functionally identical. Both return the same data and have identical EXPLAIN and PROFILE results. For this specific query there’s no difference in the two approaches.
But one situation where there is a big difference between the two is when we’re using OPTIONAL MATCH instead of MATCH.
OPTIONAL MATCH chains
Recall that an OPTIONAL MATCH returns a row if our pattern is satisfied, and NULL if not – it’s basically an OUTER JOIN but expressed in a graph query.
Let’s look at a fairly contrived example using the Movies database. Here, we want every Movie and the list of people who produced it, if any are known. We use OPTIONAL MATCH because not all Movies have producers in our database, but we still want to return the Movie title.
MATCH (m: Movie)
OPTIONAL MATCH (producer: Person)-[:PRODUCED]->(m)
RETURN m.title, collect(producer.name)
// 38 records returned
38 records are returned, one for each Movie in the database, of which 10 have a non-empty collection of producer names.
What if we now also wanted to list the names of anyone who reviewed those films, alongside the producers. We can chain two OPTIONAL MATCH statements for this:
MATCH (m: Movie)
OPTIONAL MATCH (producer: Person)-[:PRODUCED]->(m)
OPTIONAL MATCH (reviewer: Person)-[:REVIEWED]->(m)
RETURN m.title, collect(producer.name), collect(reviewer.name)
We still get 38 records, some of which have a producer (like The Matrix and Jerry Maguire) and some of which have a reviewer (like Jerry Maguire and The Replacements). Most records only have one or the other – a few have both.
You might look at that query and wonder, “can’t we simplify that by doing all the OPTIONAL MATCHes in one go?”. It might look like this:
MATCH (m: Movie)
OPTIONAL MATCH (producer: Person)-[:PRODUCED]->(m),
(reviewer: Person)-[:REVIEWED]->(m)
RETURN m.title, collect(producer.name), collect(reviewer.name)
Well – no, you can’t. The two queries are expressing different things. The commas in the second query’s OPTIONAL MATCH are expressing a single pattern – we need to find a Person who :PRODUCED the movie, and a Person who :REVIEWED the movie to return anything from the optional match at all. If we can’t match any part of the comma-separated portions of the pattern, we’ll return nothing at all.
We no longer return any producer or reviewer information for The Matrix, nor The Replacements. The Matrix has a producer but no reviewer, and the Replacements has a reviewer but no producer.
IRSA, or ‘IAM Roles for Service Accounts’ is a new AWS mechanism that lets pods running in your EKS cluster automatically assume an IAM role when using other AWS resources.
For example, we might have a DynamoDB with a read-write role associated, and we want a payment processing pod in our cluster to write to it. IRSA should make this pretty transparent.
First off, follow this tutorial. The rest of this post is basically an errata sheet for the missing information and steps to get it working.
Our approach
We’re going to tackle this in two sections:
Get the s3-echoer example app working in our cluster – this proves the cluster setup is correct
Amend our application to correctly use IRSA
Getting the cluster configuration right
If you’re using Terraform…
Two possible screw-ups here depending on which tutorial you’re following – I went with this one, which needs some tweaks:
OpenID Provider CA thumprints missing
Using Terraform to spin out your cluster? This bug will currently leave the OpenID Connect provider in an invalid state, because no certificate thumbprints are added. You’ll need to either hack some Bash into your build, or hard-code the CA thumb in your .tf file. The hacking method is fine if you’re only ever targeting one AWS region. Without this step, you will find that the s3-echoer portion of the original tutorial fails.
Wrong role assumption policy
The tutorial adds a policy to your service account role that limits who can assume the role to your aws-node pods running in your cluster. Since your code will be running in your own pods using your own service account, you need to use your own namespace and service account name instead. For example, if our deployment were under a service user called ‘payments-service-user’ running in the default namespace, we’d want:
You should now be at a point that you can get the s3-echoer to run.
You can check if your own cluster’s service account is setup OK by Bash’ing into any pod and running the env command. We need the following three environment variables set:
AWS_DEFAULT_REGION
AWS_ROLE_ARN
AWS_WEB_IDENTITY_TOKEN_FILE
Amending our application
While the SDKs just work with other AWS hosting models, you need to do some manual work to get EKS IAM role assumption to work. This isn’t consistent across SDK languages – the Go SDK seems to fall into the Just Works category, but others like the Java SDK need a tweak.
In Java, in particular, you need to add an instance of STSAssumeRoleWithWebIdentitySessionCredentialsProvider to a credentials chain, and pass that custom chain to your SDK init code via the withCredentials builder method.
This class doesn’t automatically come as part of the credentials chain. Nor does it automatically initialise itself from environment variables the same way other providers do.
You’ll have to pass in the web identity token file, region name and role ARN to get it running.
TL;DR: You can pull the 3GB clone of the Catalog API , though note that it will unpack to 4.8 million files over 1.6 million folders and weigh in at about 52GB uncompressed.
You can pull the .NET Core console application that produced the clone from GitHub.
NuGet is the .NET package manager, and https://nuget.org hosts almost all publicly-published NuGet packages. A package is essentially a ZIP file with a metadata component and some binaries. The metadata portion details version and author information, descriptions and so on – it also lists the dependencies of the package upon other packages in the ecosystem using SemVer.
Package management data sources like this are interesting for playing around with graphs. They’re big, well-used, well-structured data sets of highly connected data . At time of writing, there are 167,733 unique packages published with over 1.8 million versions of those packages listed.
As part of an upcoming series, I wanted to load that information into a Neo4j graph database to see if there were any interesting insights or visualisations we could create when given access to such a big data set. Unfortunately each call to the API takes between 100ms and 500ms – doesn’t sound like much, but if you’re pulling 4.8 million documents you’re looking at around 23 days of time just sequentially pulling files.
You also have to process the files sequentially – each catalog page has a commit timestamp that gives it a strong ordering, and catalog entries are essentially events that have happened to a package version. It’s possible a single package version has multiple different package metadata pages associated with it spanning an arbitrary period of time as the package is listed, de-listed or metadata amended.
I wanted to have Neo4j load the data via REST API calls, rather than going with a standard file load as that was the point of the exercise. This meant that not only did I have to clone the dataset, but I had to host it locally so that it looked like the live API.
Catalog API
The Catalog API exposes every version of every package published to NuGet. Publishes and updates to published packages are recorded as separate documents, and the catalog is paged into batches of 500 or so changes per batch, plus or minus.
There are nearly 9,000 batches reported by the Catalog API, and a total of around 4.8 million documents. Some of those documents relate to the same version of a package – for example, when a package gets de-listed for some reason there will be an updated document in one of the Catalog API pages detailing the new state of the package.
There’s no rate limit on the Catalog API – it’s just files hosted in Azure blob storage – and each document contains navigable URLs to related information. If we wanted to pull a clone of the Catalog API, we could just start from the root document and crawl the links found.
Cloning the documents
Even though Neo4j needs to process the files sequentially, we don’t need to clone them sequentially. To retrieve 4.5 million documents in any sensible amount of time, we need to go multi-threaded. I bashed together a quick .NET console app to do just that.
The app just a pretty simple breadth-first search of links found in documents. We start off with the catalog root URL which details the URL of each of the 8,800 ish catalog pages:
We then search for anything that looks like a URI within the file, check we’ve not already processed that URI and then add it to a ConcurrentQueue. Since the .NET BCL doesn’t have a ConcurrentSet, we use a ConcurrentDictionary and just care about the keys within it.
The queue ends up containing 4.8 million items at its peak, and the ‘processed files set’ slowly grows as the queue is drained.
We spin out 64 System.Threading.Tasks.Task objects in an array. Each Task takes a single URI from the queue, quickly validates that we actually have work to do, pulls the contents of the file and parses out any new URIs. Each new URI is added to the processing queue, and the contents of the file are written to disk in a folder structure that mirrors the segments of the URI so that we can easily host it later. The Task then polls the queue again and waits until there’s more work to do, or until the queue is drained of work items.
The method doing the work just spins on the queue until we run out of work to do
Every minute or so a watchdog Task clones the work queue and the ‘processed’ set and persists them to disk. Fun fact – awaiting a WriteLineAsync is incredibly slow relative to just letting it block, especially when you’re calling it millions of times in a loop.
On startup, the app looks for these checkpoint files and reloads its state from them if found – that way we can pause the processing by just killing the process.
At peak the process was using around 2GB of RAM and pulling down files at around 10MBps.
You can find the source for the application on GitHub, as well as a link to the but the tool itself would need more work before you could for example resume from a snapshot tarball such as this.
24 hours later, what I ended up with was… extensive.
Just calculating the summary took twelve minutesThe unnerving feeling of seeing 1.6 million folders in a single folder doesn’t really go away
Now what?
Serving a mirror of the Catalog API with Nginx
Now that we’ve got our archive of files, we can spin out a super simple docker-compose script to host Nginx, serve the files from some URL and then replace our usages of api.nuget.org with localhost:8192 or whatever.
First off, the docker-compose file – we’re assuming that the file lives in the same folder as the api.nuget.org root folder of documents:
You’ll have to make sure Docker has access to the drive where the mirrored files are stored to pull this off. We just serve that folder directly as Nginx’s default document base, but then also map in a file to configure Nginx to rewrite any URL that looks like ‘api.nuget.org’ to point to localhost:
Because the crawler just saved files to a directory structure that matches the URI components, we can trivially serve the files without needing to translate names.
A quick docker-compose up and we’re off to the races:
Of course, we could just use the .JSON files directly, without getting Nginx in the way but since the Neo4j post I did this for was about crawling a REST API, it seemed like a bit of a cheat to just index files on disk instead.
Downloads
You can download the archive – it’ll take… some time to decompress, and you’ll end up with around 52GB of space consumed on the drive once you’ve done so, as well as 4.8 million new files and 1.6 million new folders so maybe do this on a drive you don’t care that much about.
The source for the crawler is available on GitHub though it’s super rough-and-ready and provided with absolutely no guarantees, aside from that it’s likely to make your day worse by running it.
Neo4j 4.0 brings fine-grained access control and general RBAC capabilities to the table. MR2 has started showing how these features are going to work, though they’re only available in the Enterprise edition and MR2 is obviously pre-release so very much not production-ready.
Role support
A role is a collection of zero or more privileges assigned to zero or more users. Roles let you collect together the privileges required to accomplish some task. By allocating a role to a user, you in essence have them take on the privileges of the role in conjunction with any other roles they have. If you add a privilege to a role, all users with that role immediately have the new privilege.
Privilege support
As of MR2, Neo4j supports four privileges:
READ – the ability to read properties of the object being secured
TRAVERSE – the ability to include the object in a graph traversal – that is, the ability to find the node or relationship at all
MATCH – a combination of the READ and TRAVERSE privileges
WRITE – the ability to modify nodes, relationships and properties. In MR2 this isn’t as tightly defined as the other roles (though it will be eventually), and doesn’t really count as fine-grained but in its current form it does at least let you support read-only users by not including the WRITE privilege
WRITE is currently a graph-wide ‘insert/update/delete’ privilege, though support for finer-grained label-based control is coming. READ, TRAVERSE and MATCH are more interesting.
Privileges are granted to Roles, which are allocated to Users.
Cloudbooks – an imaginary SaaS provider
We need an example graph to explore this stuff, so: Cloudbooks is an imaginary provider of accounting software. Their software is multi-tenant, which means that all of their customers inhabit a single database in the cloud.
Neo4j is used amongst other things to track which features of the software users are interacting with. Our data model is roughly as follows:
A Tenant (in red) has multiple Users (brown) as members. Each User may have used zero or more Features (green).
Getting setup – Neo4j 4.0 MR2 Enterprise in Docker
RBAC functionality is only available in Neo4j Enterprise edition, so let’s spin out a Docker container with it in.
Things have changed in Neo 4.0 – there’s now support for multiple databases. When we first log in using Neo4j Browser we’ll be connected to the default ‘neo4j’ database, but we also have an option to use the ‘system’ database. The system database is where we can create new databases as well as define roles, create users and assign access to roles using the new RBAC functionality so let’s do that.
We’ll create a new database called ‘cloudbooks’, then add some sample data to it.
Support – these members of the Cloudbooks team support staff can view all records in the system
Analyst – this role represents data analysts who might analyse feature usage by tenant. These users aren’t allowed access to information about individual users of the Cloudbooks system
While we’re at it, we’re going to create two new users, one per role
supportuser
analystuser
Each user’s password is just their username again, since this is just a test.
:use system
CREATE USER supportuser SET PASSWORD 'supportuser' CHANGE NOT REQUIRED
CREATE USER analystuser SET PASSWORD 'analystuser' CHANGE NOT REQUIRED
CREATE ROLE Support
CREATE ROLE Analyst
GRANT ROLE Support TO supportuser
GRANT ROLE Analyst to analystuser
If we log in as any of those users, we’ll find that by default we have no privileges at all.
Let’s allocate some privileges to the roles.
Graph-wide privileges
Neo4j 4.0 supports graph-wide privileges – that is, we can specify a privilege be allocated to every node and relationship in the graph without needing to call out specific labels or relationship types.
Let’s give the Support role read access to the entire graph:
:use system
GRANT MATCH (*) ON GRAPH cloudbooks TO Support
If we log in as the support user we can check that we see the whole graph:
But we can’t make any modifications to the graph:
Good – that’s basic, graph-wide RBAC working.
The READ privilege and how DENY works
Let’s look at the following query, first:
MATCH (t: Tenant)<-[:MEMBER_OF]-(:User)-[:USED]->(f: Feature)
RETURN t.id as `Tenant ID`,
f.name AS `Feature Name`,
count(*) AS `Usage Count`
ORDER BY `Tenant ID`, `Feature Name`
We want to list, per tenant, the features they’re using and how often they’re getting used. Our result if we log in as the admin account (which can see and do everything) is what you’d expect:
Notice that we don’t actually care which User used the feature, nor do we return any information about them – we just traverse that node to get the insights we want.
We could use a Deny permission on User so prevent anyone in the Analysis group from reading user details – we’re going to drop and recreate the role here to properly clean up behind the scenes, as there seems to be a couple of issues at the minute in MR2 with REVOKE not quite cleaning house how it should:
:use system
DROP ROLE Analyst
CREATE ROLE Analyst
GRANT ROLE Analyst to analystuser
GRANT MATCH (*) ON GRAPH cloudbooks TO Analyst
DENY READ (*) ON GRAPH cloudbooks NODES User TO Analyst
If we log in as our analystuser account we’ll find that the same query still works:
But we can’t return any information about the user nodes themselves:
As with most such systems, DENY takes precedence over GRANT – even though we have MATCH on everything in the graph we still can’t read information from the privileged User nodes because of the DENY rule.
Property-specific privileges
Neo has nulled-out properties on the User object because we’ve got a DENY rule on our role. Let’s relax that a bit, and allow access to user IDs, but not user names.
DROP ROLE Analyst
CREATE ROLE Analyst
GRANT ROLE Analyst to analystuser
GRANT MATCH (*) ON GRAPH cloudbooks NODES User TO Analyst
DENY READ (name) ON GRAPH cloudbooks NODES User TO Analyst
READ and MATCH both support specifying one or more properties to allow or deny access to, with the (*) wildcard representing ‘all properties’. In the above, the DENY READ (name) privilege prevents us from reading the ‘name’ property of User nodes, but since no other DENY exists for other properties on User nodes we can cheerily read out the user’s ID.
The TRAVERSE privilege vs the MATCH privilege
We’ve been using the MATCH permission above, which is a combination of READ and TRAVERSE. Let’s see what happens if you just use one or the other.
We’ll grant MATCH on everything except User, and then try the two fine-grained controls on just User nodes.
The TRAVERSE privilege
DROP ROLE Analyst
CREATE ROLE Analyst
GRANT ROLE Analyst to analystuser
GRANT MATCH (*) ON GRAPH cloudbooks Nodes Tenant, Feature TO Analyst
GRANT TRAVERSE ON GRAPH cloudbooks Relationships * TO Analyst
With no further permissions, our query returns no results – because we aren’t permitted to traverse User nodes, we can’t make the jump from Tenant to Feature (even though we have a TRAVERSE privilege on every relationship in the graph):
MATCH (t: Tenant)<-[:MEMBER_OF]-(u:User)-[:USED]->(f: Feature)
RETURN t.id as `Tenant ID`,
f.name AS `Feature Name`,
u.name AS `User name`,
u.id AS `User ID`,
count(*) AS `Usage Count`
If we add the TRAVERSE privilege into the Analyst role on User nodes:
GRANT TRAVERSE ON GRAPH cloudbooks Nodes User TO Analyst
We start getting results again. We’ve had to include a TRAVERSE privilege on both the User node and the relationship types into and out of that node that we wanted to query on.
Because our privileges don’t extend to READ on the User node’s properties, we don’t get any data back about the user:
The MATCH privilege
MATCH is a combination of READ and TRAVERSE, so we would expect a MATCH privilege on User nodes to let us read out the properties of those nodes in a way TRAVERSE wouldn’t. Let’s try it:
GRANT MATCH (id) ON GRAPH cloudbooks NODES User TO Analyst
Wrap-up
Neo’s new RBAC functionality isn’t finished yet, and in MR2 things like the WRITE privilege not being fine-grained and REVOKE not cleaning things up properly are issues that will be fixed.
That said, it’s super promising and the splitting out of TRAVERSE from READ (and ability to specify privileges at the node and relationship level separately) will allow some interesting data protection scenarios to be cooked up.
This is the last in a series of posts where we created a Neo4j model of the Minecraft crafting tree and played around with querying it to build a shopping list for any given item.
We found data quality issues and corrected them, but finding them was made easier because of Neo4j Browser’s easy visualisation of our graph. You can see data issues quicker than you can query for them, and a human will spot anomalies pretty quickly. For example:
Isolated nodes where you expected a fully-connected graph
Cycles in the graph where you expect it to be acyclic
Multiple relationships between nodes where you expect only a single relationship
If you’re working with a large dataset (remember: the Minecraft dataset was just a toy) you could consider sampling your source data and testing your ingest on that sample. You may not find all data issues in the sample, but quickly visualising and proving out your graph model is much easier if you can fit the whole model on a few screens.
Neo4j is radical overkill for this specific problem
We knew this going in to it – we don’t need a proper database for this, we could just as well have represented the whole graph in memory in Javascript and gotten the same answers out.
That said – while we’re not using any large fraction of the power of Neo4j for our example, we did touch upon a good few core concepts:
Data loading via LOAD CSV and MERGE
Constraints and indexes
Visualisation
Querying in Cypher
Aggregation in Cypher
APOC
APOC is huge and very capable
We used a single function from the APOC library which boasts over 450 functions exposed to your Neo4j instance. It addresses a lot of functionality shortfalls in Cypher, and if you start digging into it further features like graph refactoring support, virtual nodes and node grouping all become very attractive tools for your mental toolkit.
I’m surprised it’s not just bundled by default.
It’s tempting to write APOC calls or application code over pure Cypher
I still haven’t found the dividing line yet where I’m comfortable saying ‘just express that in Cypher’ or ‘just use APOC’. We found two queries that were broadly equivalent, one in some fairly long-winded Cypher and what amounted to a one-liner in APOC. Was one better than the other?
If you’re a developer and you take the dependency on APOC to express a query then you’re buying your future self (and future colleagues) into that ecosystem. You can probably express almost any Cypher concept in a series of APOC calls – should you? Your future self now has to remember exactly how, for example, apoc.path.subgraphAll works to figure out what a query’s up to, while the plain Cypher was easier to figure out from first-principles.
There isn’t just one way to model your domain
Neo4j claims that, and I’m paraphrasing, ‘your whiteboard model is your data model’ and that’s true – we literally did that, replete with a photo of our whiteboard.
However, if you can represent something multiple ways on your whiteboard then that doesn’t save you from the underlying domain complexity. There isn’t just one way to model your domain, and the model you choose has implications on:
How easy it is to query the graph
Whether you need application code in places where you could have been using Cypher
How easy it is to ingest new data and maintain consistency within your model
Performance
…
The list goes on. We only looked at two representations of our data – there were more we could have explored. The accepted guidance seems to be to optimise your data model around the most common query or queries you’ll be performing – i.e. cover the 80% case and worry about the long tail of other queries later.
Graph refactoring and experimentation is easy
Luckily Neo4j makes it super easy to refactor your graph, and either APOC or the Neo4j cypher-shell let you export and re-import data or subsets of your data to try experiments quickly.
In addition Neo4j Desktop is very capable and a whole lot easier to use than the old days where you had to stand up new instances of the database or play with configuration files to swap graphs in and out. Installing APOC takes two clicks, and staying on the latest database version is as easy and choosing from a drop-down box.
Conclusions
The graph model we chose made certain operations more difficult. Still – we overcame the issues we had either with Cypher or application code, and built something that answers interesting questions from the graph.
Our Minecraft example wasn’t a good use-case for Neo4j as it stands, but modelling BOMs in Neo4j is a good fit in general (which is what we started to show in our simplified example back in Part 4).
Being able to answer questions like ‘what’s the most contrived item to build’ may sound frivolous, but in manufacturing translates to:
Lead-time estimation – from materials ingest, how long before step X of the process can expect work, and how long is our production pipeline in minutes/hours?
Quality and yield modelling – what’s the cost of rework for a defect found at a particular part of the process?
Design-for-manufacture decision making support – how many different fastenings are used across the product, can we reduce that?