




If you come from a SQL background, you would probably not expect aliasing a column or table to have a measurable impact on performance.
Not quite so in Cypher.
Let’s build a sample graph of one million nodes (Neo4j Desktop running 3.5.13 Enterprise, 16GB max heap, 8GB initial heap):
CREATE CONSTRAINT ON (n: Node) ASSERT n.id IS UNIQUE
FOREACH (r in range(1, 1000000) | MERGE (n: Node { id: r }))
RETURN 1Profiling a basic query on :Node(id) shows that we’re hitting the index just fine and this query runs quick as you like:
PROFILE MATCH (n: Node)
WHERE n.id = 123456
RETURN n
// 2 total db hits in 1 ms
If we introduce a WITH into the mix, before the WHERE clause – what would you expect? Let’s add a redundant one and see:
PROFILE MATCH (n: Node)
WITH n
WHERE n.id = 123456
RETURN n
// 2 total db hits in 0 ms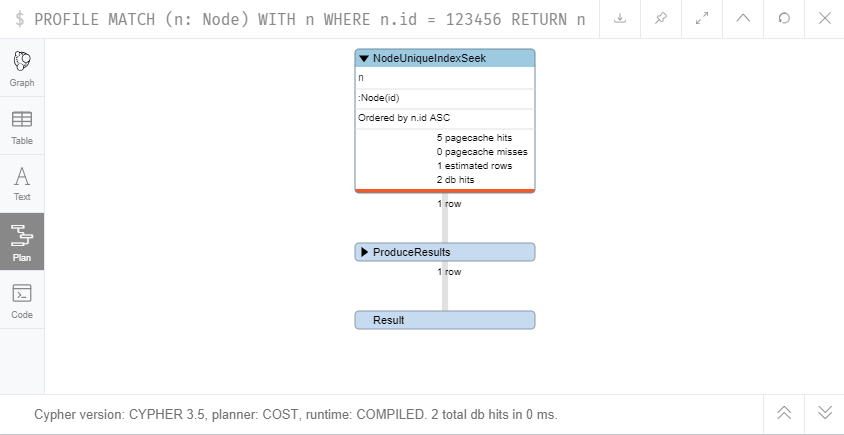
No difference, nor would you expect one – the WHERE clause obviously relates to an indexed property, irrespective of the WITH.
What then if we give the WITH an alias?
PROFILE MATCH (n: Node)
WITH n as nAlias
WHERE nAlias.id = 123456
RETURN nAlias
// 2000001 total db hits in 422 ms
Even though to your eye that’s the same query, the optimiser in Neo4j has lost track of the indexability of the query, and we’re down to a NodeByLabelScan of 1,000,000 nodes.
I’d argue this is an optimiser bug, and have raised a bug for it (though it’s likely super low priority, and I suspect the sort of thing that sounds easier to fix than it actually is).
Still, it’s easy to fall into this sort of trap when refactoring big queries. For clarity and safety, if you’re going to try to hit an index do it in a WHERE clause attached directly to your MATCH. And regardless, re-profile your queries after refactoring them as part of your validation.