This is the last in a series of posts where we created a Neo4j model of the Minecraft crafting tree and played around with querying it to build a shopping list for any given item.
We found data quality issues and corrected them, but finding them was made easier because of Neo4j Browser’s easy visualisation of our graph. You can see data issues quicker than you can query for them, and a human will spot anomalies pretty quickly. For example:
Isolated nodes where you expected a fully-connected graph
Cycles in the graph where you expect it to be acyclic
Multiple relationships between nodes where you expect only a single relationship
If you’re working with a large dataset (remember: the Minecraft dataset was just a toy) you could consider sampling your source data and testing your ingest on that sample. You may not find all data issues in the sample, but quickly visualising and proving out your graph model is much easier if you can fit the whole model on a few screens.
Neo4j is radical overkill for this specific problem
We knew this going in to it – we don’t need a proper database for this, we could just as well have represented the whole graph in memory in Javascript and gotten the same answers out.
That said – while we’re not using any large fraction of the power of Neo4j for our example, we did touch upon a good few core concepts:
Data loading via LOAD CSV and MERGE
Constraints and indexes
Visualisation
Querying in Cypher
Aggregation in Cypher
APOC
APOC is huge and very capable
We used a single function from the APOC library which boasts over 450 functions exposed to your Neo4j instance. It addresses a lot of functionality shortfalls in Cypher, and if you start digging into it further features like graph refactoring support, virtual nodes and node grouping all become very attractive tools for your mental toolkit.
I’m surprised it’s not just bundled by default.
It’s tempting to write APOC calls or application code over pure Cypher
I still haven’t found the dividing line yet where I’m comfortable saying ‘just express that in Cypher’ or ‘just use APOC’. We found two queries that were broadly equivalent, one in some fairly long-winded Cypher and what amounted to a one-liner in APOC. Was one better than the other?
If you’re a developer and you take the dependency on APOC to express a query then you’re buying your future self (and future colleagues) into that ecosystem. You can probably express almost any Cypher concept in a series of APOC calls – should you? Your future self now has to remember exactly how, for example, apoc.path.subgraphAll works to figure out what a query’s up to, while the plain Cypher was easier to figure out from first-principles.
There isn’t just one way to model your domain
Neo4j claims that, and I’m paraphrasing, ‘your whiteboard model is your data model’ and that’s true – we literally did that, replete with a photo of our whiteboard.
However, if you can represent something multiple ways on your whiteboard then that doesn’t save you from the underlying domain complexity. There isn’t just one way to model your domain, and the model you choose has implications on:
How easy it is to query the graph
Whether you need application code in places where you could have been using Cypher
How easy it is to ingest new data and maintain consistency within your model
Performance
…
The list goes on. We only looked at two representations of our data – there were more we could have explored. The accepted guidance seems to be to optimise your data model around the most common query or queries you’ll be performing – i.e. cover the 80% case and worry about the long tail of other queries later.
Graph refactoring and experimentation is easy
Luckily Neo4j makes it super easy to refactor your graph, and either APOC or the Neo4j cypher-shell let you export and re-import data or subsets of your data to try experiments quickly.
In addition Neo4j Desktop is very capable and a whole lot easier to use than the old days where you had to stand up new instances of the database or play with configuration files to swap graphs in and out. Installing APOC takes two clicks, and staying on the latest database version is as easy and choosing from a drop-down box.
Conclusions
The graph model we chose made certain operations more difficult. Still – we overcame the issues we had either with Cypher or application code, and built something that answers interesting questions from the graph.
Our Minecraft example wasn’t a good use-case for Neo4j as it stands, but modelling BOMs in Neo4j is a good fit in general (which is what we started to show in our simplified example back in Part 4).
Being able to answer questions like ‘what’s the most contrived item to build’ may sound frivolous, but in manufacturing translates to:
Lead-time estimation – from materials ingest, how long before step X of the process can expect work, and how long is our production pipeline in minutes/hours?
Quality and yield modelling – what’s the cost of rework for a defect found at a particular part of the process?
Design-for-manufacture decision making support – how many different fastenings are used across the product, can we reduce that?
Last time we found that writing the query that told us which items to gather from the world to build any given item was between tricky and impossible to express in one Cypher query without some application code.
We outlined an algorithm that used a simulated shopping list to keep track of what we needed to run for each Recipe in the tree.
Rather than walk through the build of that here, I’ve had a stab some something poorly approximating Literate Programming and posted the code in a Gist that I’ll also embed here:
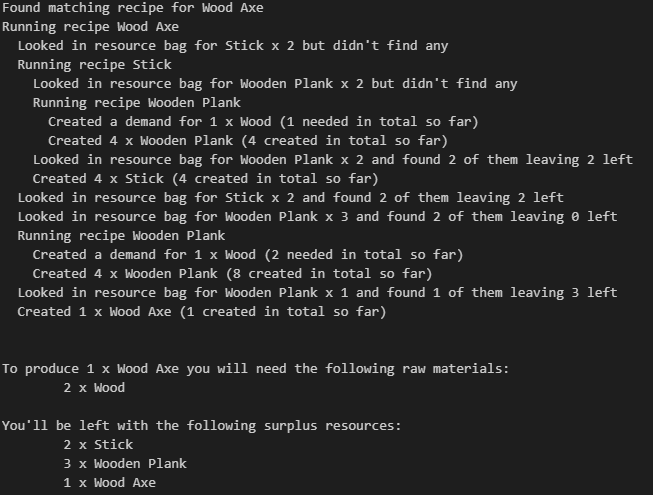
Let’s try it out then – our previous Cypher query told us that we needed 1x Wood to build a Wood Axe but that was wrong, so how does the new algorithm work out?
That’s looking tidier, we need 2x Wood.
How about producing a Carrot on a Stick?
We can see from the indentation in both shots how each Recipe ends up running other Recipes recursively until we finally hit resources that have no Recipe – raw materials.
Next steps
We’re not going to go any further with this application – we’ve tried a few things out, explored how far we can push Cypher for our use case and pulled together a quick Node app to talk to the database to do the heavy-lifting when we couldn’t manage in Cypher.
Next time we’ll do a quick retrospective on the project to wrap things up.
In the last post we found that while there are different ways to represent the Minecraft crafting list in a graph database, just generating a list of materials to be gathered for a given recipe is not straightforward.
In this post we’ll look at what we could do in pure Cypher if Minecraft were a slightly different game. We’ll then rough out an algorithm to walk a requirements tree for a given Recipe and figure out what materials we need to gather that does work with Minecraft.
Note: This post will continue with our ‘Recipe’-based graph from Part 3, where Resource and Recipe nodes are separate. You can download the state of our database so far via this Gist, which is a Cypher script to be run into a clean graph.
What if Recipes produced only one output unit?
If Minecraft were different, and a Recipe only ever produced one unit of output then we could actually create an ingredients list for any item just in Cypher.
Remember earlier we had two ways to produce the ‘path’ from a given Resource to its constituent ingredients, listing all the intermediate Recipes. Let’s look again at the clumsier, non-APOC version for a Carrot on a Stick:
MATCH (r: Resource { name: 'Carrot on a Stick' })<-[:PRODUCES]-(recipe1: Recipe)-[req1:REQUIRES]->(dep1: Resource)
OPTIONAL MATCH (dep1)-[:PRODUCES]-(recipe2: Recipe)-[req2:REQUIRES]->(dep2: Resource)
OPTIONAL MATCH (dep2)-[:PRODUCES]-(recipe3: Recipe)-[req3:REQUIRES]->(dep3: Resource)
OPTIONAL MATCH (dep3)-[:PRODUCES]-(recipe4: Recipe)-[req4:REQUIRES]->(dep4: Resource)
RETURN r, recipe1, dep1, recipe2, dep2, recipe3, dep3, recipe4, dep4
One thing to note is that this gives you three rows of results – one for each full subtree from the Carrot on a Stick node to a terminal raw-ingredient node.
Here’s another, this time for Wood Pickaxe:
This example’s arguably more interesting – the Pickaxe is made of Sticks and Planks. Sticks are themselves made of Planks – that means there’s two sub-trees to terminal nodes:
The tree that creates the Sticks for our Pickaxe (Sticks -> Planks -> Wood)
The tree that creates the Planks for our Pickaxe (Planks ->Wood)
Both trees end in the same resource, unlike the Carrot on a Stick case.
What we want here is to group the information by the name of the resource in the terminal nodes, and multiply together the input quantities down the tree. Why multiply? Consider the Pickaxe case in our simplified model of Minecraft (where each recipe outputs just one resource), and just look at the ‘Sticks’ component of our tree.
A Pickaxe requires 2x Sticks and 3x Planks
Each Stick requires 2x Plank
Each Plank requires 1x Wood
The total Wood needed in this case is:
(Wood per Plank) * (Planks per Stick) * (Sticks per Pickaxe)
= 1 * 2 * 2
= 4
How does grouping work in Neo4j and Cypher?
If you use any aggregate function (like sum, count, etc) then Neo4j will group by the previous non-aggregate values to compute the value you’re asking for. Let’s see an example by amending the RETURN statement of our previous query to just return the number of times a given Resource appeared in our result set (which will be the number of subtrees that end with that resource):
MATCH (r: Resource { name: 'Wood Pickaxe' })<-[:PRODUCES]-(recipe1: Recipe)-[req1:REQUIRES]->(dep1: Resource)
OPTIONAL MATCH (dep1)-[:PRODUCES]-(recipe2: Recipe)-[req2:REQUIRES]->(dep2: Resource)
OPTIONAL MATCH (dep2)-[:PRODUCES]-(recipe3: Recipe)-[req3:REQUIRES]->(dep3: Resource)
OPTIONAL MATCH (dep3)-[:PRODUCES]-(recipe4: Recipe)-[req4:REQUIRES]->(dep4: Resource)
RETURN COALESCE(dep4.name, dep3.name, dep2.name, dep1.name), count(*)
That matches our previous analysis. So how do we get the total number of Wood we need? Well, multiplying the quantities together directly won’t work because sometimes the values will be null. Examine the first row of the query before last:
The variables recipe3, dep3, recipe4 and dep4 are all NULL because that sub-tree doesn’t go deep enough that they’re needed – after two hops we’ve hit Wood and there’s no further to go. And Neo4j, just like every other database, will return NULL on mathematical operations involving NULL as an operand. For instance:
4 * NULL = NULL
2 + NULL = NULL
We need to turn all those NULLs into 1s so that we can safely, blindly multiply them without changing the result of the calcuation. We can use the COALESCE operator for this, giving us this final query:
MATCH (r: Resource { name: 'Wood Pickaxe' })<-[:PRODUCES]-(recipe1: Recipe)-[req1:REQUIRES]->(dep1: Resource)
OPTIONAL MATCH (dep1)-[:PRODUCES]-(recipe2: Recipe)-[req2:REQUIRES]->(dep2: Resource)
OPTIONAL MATCH (dep2)-[:PRODUCES]-(recipe3: Recipe)-[req3:REQUIRES]->(dep3: Resource)
OPTIONAL MATCH (dep3)-[:PRODUCES]-(recipe4: Recipe)-[req4:REQUIRES]->(dep4: Resource)
RETURN COALESCE(dep4.name, dep3.name, dep2.name, dep1.name), sum(coalesce(req4.qty, 1) * coalesce(req3.qty, 1) * coalesce(req2.qty, 1) * coalesce(req1.qty))
Does it work for Carrot on a Stick?
Good!
Can we make it work for the real rules of the game?
Our toy above works because we cheated. But could we make it work if we allow multiple outputs per recipe?
The actual answer for Carrot on a Stick, if we work it out by hand, is:
1x Carrot
2x String
1x Wood
The Carrot and the String are straightforward raw materials needed directly by the Carrot on a Stick recipe itself. The Wood comes in to it because we need to make:
3x Sticks
Sticks require 2x Wooden Planks – but we produce 4 Sticks for each run of the recipe so 2x Wooden Planks is enough to cover all the Sticks we need
Wooden Planks require 1x Wood – but we produce 4 planks for each run of the recipe so 1x Wood is enough to cover all the Wooden Planks we need
Since our graph has the output quantity of a Recipe encoded on the :PRODUCES relationship qty property, could we divide the input requirement by the output requirement to get to what we want?
Let’s try. We’ll need to add variables for the :PRODUCES relationships now, as we need that qty property for our maths.
We need to case the quantities to floating point integers, as otherwise Neo4j will do integral division, meaning we can’t do maths on the fractions of resources we might need to build a given item
We divide the requirement for a given recipe by the output quantity to get in essence the number of times that recipe needs to run to yield the correct amount of output
We ceil the result, as a requirement for (for example) 1.5x Wood is really a requirement for 2x Wood since we can’t collect Wood in any smaller unit
This almost certainly doesn’t actually work, because we can’t just directly do maths like this.
Close but not quite
Let’s look at the example of a Wood Axe. To make a Wood Axe we need:
2x Sticks
3x Wood Planks
Let’s do the same analysis as we did before:
To make 2x Sticks we need 2x Wood Planks
To make 2x Wood Planks we need 1x Wood
To make the remaining 3x Wood Plank we need a further Wood for a total of 2 Wood
So why does our query tell is that we only need 1x Wood?
Our query doesn’t discern between the different reasons our recipe tree needs Wood. In its ‘mind’:
To make 2x Sticks is 0.5 units of output of the Stick recipe (since it outputs 4x Sticks at a cost of 2x Wood Planks)
To make 2x Wood Planks is 0.5 units of output of the Wood Plank recipe (since it outputs 4x Wood Planks at a cost of 1x Wood) – so we need 0.5 * 0.5 = 0.25 units of Wood to produce 2x Sticks
To make the remaining 3x Wood Planks is 0.75 units of output of the Wood Plank recipe by the logic above – so we need 0.75 units of Wood to produce the remaining 3x Wood Planks
We therefore need 0.25 + 0.75 = 1x Wood in total
The query’s fallen down because it’s assuming we can run Recipes a fractional number of times and not handling the input quantities correctly as a result:
To produce Sticks in bundles of 4 requires 2x Wooden Planks – even though we only need 2x Stick we still need to burn 2x Wooden Planks to make them
It’s on this step that the earlier query really falls down
We need 3x Wooden Planks directly in the Wood Axe recipe for a total of 5x Wood Planks
To make 5x Wood Planks requires 2x runs of the Wood Plank recipe, each run of which consumes 1x Wood
An algorithm for application code
Let’s stop thinking about this in Cypher terms for a minute and design a way to walk the Recipe tree that’ll give us correct answers.
Suppose we maintain a table with three columns:
The name of a Resource
The number of that Resource that we’ve created running Recipes
The number of that Resource that we require to run the Recipes so far
Each time we want to obtain some resource, we’ll figure out if it’s produced by Recipes or a raw material.
If it’s a raw material, we just increase the ‘Required’ entry in the table for that Resource by the amount we need – we can’t make more of it via a Recipe.
If it’s produced by a recipe, we need to do a bit more work because there are three cases:
The ‘already in stock’ case
Say we’ve run the Sticks recipe once already for some other step, and consumed 1x Stick. The Sticks recipe outputs 4x Sticks, so our resource table might look like:
Resource
Created
Required
Stick
4
1
We are now trying to make something else requiring a further 2x Stick. While there’s a Recipe for this, we don’t need to run it because we have a surplus of 3x Stick already.
In this case, we just increase the ‘Required’ column by the amount we need and don’t bother running the Recipe again.
The ‘entirely out of stock’ case
Say we’ve not run the Sticks recipe at all yet, but have a need of 6x Sticks for a Recipe upstream. We don’t have any Sticks so we’ll have to run the Sticks recipe. We need to run it twice, because the Recipe outputs 4x Sticks per run and we need 6.
We run the Recipe twice, each time adding its output to the table in the ‘Created’ column. We then add 6 to our ‘Required’ column for Stick to earmark some of that output for the upstream recipe:
Resource
Created
Required
Stick
8
6
The ‘partly in stock’ case
Say we’ve run the Sticks recipe once, used 1x Stick and now need a further 4x Sticks. At the start, our table looks like this:
Resource
Created
Required
Stick
4
1
The table says we have 3x Stick going spare just now, so we have a shortfall of 1x Stick. We need to run the Stick recipe once, and add its output to the table before allocating what we need. We run the recipe:
Resource
Created
Required
Stick
8
1
Now there’s no shortfall, so we take the 4x Stick by increasing the Required column:
Resource
Created
Required
Stick
8
5
We recursively do this until we hit raw-material nodes. Because raw materials cannot be produced but must be collected from the world, we just add them to the Required column. For example, to produce a Wooden Plank, we need 1x Wood. After running the Wooden Plank recipe, our table might look like this:
Resource
Created
Required
Wooden Plank
4
1
Wood
0
1
Once we’ve hit a raw material node we can’t recurse further – it’s the base-case for our recursion.
Then, getting a shopping list is as simple as finding the cases where the required number of a Resource is non-zero but the created number is zero – that is, we need some of that Resource, but we couldn’t create any.
Next steps
Next time we’ll take that algorithm and bake it into a quick Node command-line application where we can query for a given Resource and get back the list of ingredients we need to go and find. We’ll also see how the approach above lets us answer more interesting questions.
In this series of posts, I’m going to try to represent the Minecraft crafting tree in Neo4j. In Part 2 we imported some data, explored it a little and noticed some inconsistencies which we fixed up. We found that we can write some simple and interesting queries against it. In this post we’ll try building a shopping list for a Wooden Sword and realise that our data model isn’t right yet – then we’ll try and refactor the model to something more useful.
Note: You can download the state of our database so far via this Gist, which is a Cypher script to be run into a clean graph. You’ll be able to download the state of play after all our refactoring work from this post at the end.
A problem lurks – output quantities
So far our model is good for the dependency chain of Minecraft items (i.e. ‘some number of these things makes up item X’) but we can’t produce a list of required materials to gather for any given Minecraft item – the shopping list of items-and-quantities that we’d have to go find or mine to make it.
Our graph falls down because we’ve made a bogus assumption – that some variable number of input items produce one unit of output.
For instance – a Torch is made of 1x Stick and 1x Coal – if we have one each of one of those, we produce one Torch and all is well.
But while making Sticks requires 2x Wood, we actually output 4x Sticks for every 2x Wood that comes into the crafting bench. Our graph didn’t encode this at all, so we can’t reliably figure out how much Wood we need to produce one Stick. Or three Sticks.
Representation is everything
It’s not even clear how best to represent this. At the minute our :REQUIRES relationship has a qty attribute detailing how many of the input item it takes to build one unit of the output item. Our current model has
(stick)-[:REQUIRES { qty: 2 }]->(wood)
which is strictly true (in the sense that we can’t make a Sticks until we have 2x Wood) but obviously doesn’t reflect the actual cost of producing a Stick.
Mathematically more accurate would maybe be to allow fractional quantities – 4 Sticks are produced when we put 2x Wooden Planks together, so the cost of one Stick is in some sense 0.5 units of Wood.
(stick)-[:REQUIRES { qty: 0.5 }]->(wood)
But now we’ve lost the concept of how many input items are needed to build the smallest buildable bundle of Sticks – we can’t bring half a Wood unit to the crafting bench, half-units don’t exist at all and even if they did the recipe requires 2 units to kick off. We can’t infer that from the quantity on the relationship.
Let’s explore a couple of refactorings of our model to help.
Option 1 – add outputSize as a property on our Resource nodes
If we could reliably say that Sticks are only ever produced in bundles of 4 then we could express that on the Stick node in our graph and keep representing input quantities how we are just now (i.e. the actual amount required to kick off the crafting). For example:
Now to figure out how much it’ll cost to make a Torch we could walk the graph and do some maths along the way:
1x Coal is just found by mining
1x Stick is 0.25 of the outputSize of a Stick crafting run. Since we can’t have fractional crafting runs – we either produce 4x Sticks or none at all – we could maybe express the requirement as ceil(1 Stick / outputSize) = 1 Sticks in whatever application logic we have
To make 1x Stick requires 2x Wood
Thus the minimum requirement is 1x Coal + 2x Wood, and we’ll end up with some Sticks left over at the end
If there are multiple multiple ways to produce the same item then this falls down – and while our graph just now has only one way to produce things, Minecraft does support variations. For example, you can use an Anvil to repair any Sword by combining two of that Sword type into one.
Thus we could make a sword by building it from scratch, or by combining two broken swords into one new one. Our graph above doesn’t let us express those as different options – if we try to represent it naively we’ll make it look as though the cost of making a sword is that of all its raw ingredients, plus another sword (giving us cycles, if nothing else, and meaning we’d never be able to make the things).
So far it looks OK as an approach so long as we’re willing to accept that we can’t model there being multiple ways to make a given item (which for some games is entirely fine).
The following few statements will update our original graph with the output quantities:
// Recipes that produce 2 of something
MATCH (r:Resource)
WHERE r.name in ['Trapdoor', 'Fence', 'Blaze Powder']
SET r.outputQty = 2;
// Recipes that produce 3 of something
MATCH (r:Resource)
WHERE r.name in ['Fire Charge', 'Ladder', 'Paper', 'Sign', 'Bottle']
SET r.outputQty = 3;
// Recipes that produce 4 of something
MATCH (r:Resource)
WHERE r.name in ['Wooden Plank', 'Stick', 'Torch', 'Arrow', 'Stone Brick', 'Smooth Sandstone', 'Wood Stair', 'Cobblestone Stair', 'Bowl', 'Pumpkin Seed']
SET r.outputQty = 4;
// Recipes that produce 6 of something
MATCH (r:Resource)
WHERE r.name in ['Wooden Slab', 'Stone Slab', 'Stone Brick Slab', 'Brick Slab', 'Cobblestone Slab', 'Nether Brick Fence', 'Cobblestone Wall', 'Mossy Cobblestone Wall']
SET r.outputQty = 6;
// Recipes that produce 8 of something
MATCH (r:Resource)
WHERE r.name in ['Cookie']
SET r.outputQty = 8;
// Recipes that product 15 of something
MATCH (r:Resource)
WHERE r.name in ['Iron Bar', 'Glass Pane']
SET r.outputQty = 16;
// Give a default output quantity of 1 for everything else
MATCH (r:Resource)
WHERE r.outputQty IS NULL
SET r.outputQty = 1;
Option 2 – represent a Recipe as a first-class citizen of the graph
Option 1 is trying to work around the fact that our graph’s representing two things in one go:
The actual items being crafted – like Sticks and Pickaxes
The way in which those items are crafted – their dependencies
In short, a node in the graph represents both the output item and the recipe to make it, even though they’re two different concerns.
What if Recipes were nodes in our graph?
A Recipe:
:REQUIRES Resource nodes (where the qty attribute expresses the number required to complete the recipe)
:PRODUCES Resource nodes (where the qty attribute expresses how many of that Resource are produced for each run of the Recipe)
We could create Recipe nodes for every Resource node that has any inbound :REQUIRES edges – for example. we won’t end up with a Recipe for Wood (because you find it, you don’t craft it) but will have a Recipe for Wooden Planks.
This feels like a more correct approach somehow, so let’s explore how we might implement it.
Introducing Recipe nodes
First let’s create one Recipe node for each Resource node in the graph that has any inbound :REQUIRES edge (i.e. that isn’t a raw material):
MATCH (out: Resource)-[rel:REQUIRES]->(in: Resource)
MERGE (outRecipe: Recipe { name: out.name })
MERGE (outRecipe)-[:REQUIRES { qty: rel.qty }]->(in)
MERGE (outRecipe)-[:PRODUCES { qty: 1 }]->(out)
RETURN out, in, outRecipe
Added 137 labels, created 137 nodes, set 493 properties, created 356 relationships, started streaming 219 records after 98 ms and completed after 115 ms.
We could also delete the original :REQUIRES relationships:
MATCH (:Resource)-[rel:REQUIRES]->(:Resource)
DELETE rel
Completed after 32 ms.
And let’s throw a unique constraint on the new Recipe node’s name attribute while we’re at it.
CREATE CONSTRAINT ON (recipe: Recipe) ASSERT recipe.name IS UNIQUE
Added 1 constraint, completed after 104 ms.
Querying with Recipe nodes and pure Cypher
Our first stop should be to ask the updated graph how do you make Wooden Planks. But we’ve got a problem with this new approach – by adding in extra hops, we can’t easily use variable length path querying to figure out how to get from Wooden Plank to all its constituent raw materials and the intermediate Recipe nodes.
If we knew ahead of time that there was only one hop, then the following would work:
But if we try that trick on, say – a Stick we’ll only get as far as the Wooden Plank requirement and have to make another query to figure out how to make those:
Before we’d just have said ‘traverse as many :PRODUCES relationship hops as you need’ – recall our Wood Sword example:
MATCH path= (r:Resource { name: 'Wood Sword' })-[:REQUIRES*]->(:Resource)
RETURN path
We can’t use that trick any more – we sort-of want to wrap up the (Resource)<-[:PRODUCES]-(Recipe)-[:REQUIRES]-(Resource) double-hop and say ‘run that double-hop as many times as you need’ but that can’t really be done.
We could use a chain of OPTIONAL MATCHes and some clumsy Cypher to do the job if we knew the most hops we’d ever need. For example, we could support an ‘up to 3-hop’ traversal with two OPTIONAL MATCH clauses.
MATCH (r: Resource { name: 'Wood Sword' })<-[:PRODUCES]-(recipe1: Recipe)-[:REQUIRES]->(dep1: Resource)
OPTIONAL MATCH (dep1)-[:PRODUCES]-(recipe2: Recipe)-[:REQUIRES]->(dep2: Resource)
OPTIONAL MATCH (dep2)-[:PRODUCES]-(recipe3: Recipe)-[:REQUIRES]->(dep3: Resource)
RETURN r, recipe1, dep1, recipe2, dep2, recipe3, dep3
Here we’d just tack in extra OPTIONAL MATCH clauses for each level of depth we want to support.
Ugly but workable, and pure Cypher.
Querying with Recipe nodes and APOC
Instead, we can use APOC – the apoc.path.subgraphAll procedure lets us specify a repeating pattern of relationships to navigate and also limit the traversal to a specific min and max depth.
Here we’re using a map to configure the traversal with two properties:
relationshipFilter is an APOC filter string to express the relationships we should seek and traverse
maxLevel is the maximum depth from r we should traverse to
The documentation’ll do a better job than me, but essentially:
<PRODUCES – find :PRODUCES relationships going into our r node
REQUIRES> – from nodes linked via that :PRODUCES relationship (which we know to be Recipe nodes), find the nodes that are related via an outbound :REQUIRES relationship
The comma between the two patterns asks APOC to apply them in sequence – find a :PRODUCES relationship, then expand out from there using :REQUIRES relationships.
APOC will then iterate that process up to 10 times (our maxLevel parameter), expanding via :PRODUCES, then via :REQUIRES, then via :PRODUCES again until we run out of nodes or hit our limit.
It’s essentially the same as the other query, but now we’re relying on APOC and not just pure Cypher to do the work, and it isn’t particularly easier to read. Still – it’s good to have options.
Fixing up our output quantities
We still need to make sure that our output quantities are right. So far we have each Recipe requiring the correct quantity of materials through its :REQUIRES relationship to them, but we assumed that each Recipe only :PRODUCES one of that item. That’s not true in a number of cases, so first let’s fix that.
// Recipes that produce 2 of something
MATCH (:Recipe)-[relProduces:PRODUCES]->(r: Resource)
WHERE r.name in ['Trapdoor', 'Fence', 'Blaze Powder']
SET relProduces.qty = 2;
// Recipes that produce 3 of something
MATCH (:Recipe)-[relProduces:PRODUCES]->(r: Resource)
WHERE r.name in ['Fire Charge', 'Ladder', 'Paper', 'Sign', 'Bottle']
SET relProduces.qty = 3;
// Recipes that produce 4 of something
MATCH (:Recipe)-[relProduces:PRODUCES]->(r: Resource)
WHERE r.name in ['Wooden Plank', 'Stick', 'Torch', 'Arrow', 'Stone Brick', 'Smooth Sandstone', 'Wood Stair', 'Cobblestone Stair', 'Bowl', 'Pumpkin Seed']
SET relProduces.qty = 4;
// Recipes that produce 6 of something
MATCH (:Recipe)-[relProduces:PRODUCES]->(r: Resource)
WHERE r.name in ['Wooden Slab', 'Stone Slab', 'Stone Brick Slab', 'Brick Slab', 'Cobblestone Slab', 'Nether Brick Fence', 'Cobblestone Wall', 'Mossy Cobblestone Wall']
SET relProduces.qty = 6;
// Recipes that produce 8 of something
MATCH (:Recipe)-[relProduces:PRODUCES]->(r: Resource)
WHERE r.name in ['Cookie']
SET relProduces.qty = 8;
// Recipes that produce 16 of something
MATCH (:Recipe)-[relProduces:PRODUCES]->(r: Resource)
WHERE r.name in ['Iron Bar', 'Glass Pane']
SET relProduces.qty = 16;
Asking a basic question – how much Wood do two Wooden Planks take to produce?
We know a Wooden Plank recipe requires 1x Wood to kick off, and produces 4x Wooden Plank. In this case then, making 2x Wooden Plank requires we run the Wooden Plank recipe once (as 4 > 2), which requires 1x Wood. We can’t run the Recipe a fractional number of times, we just over-produce.
In this series of posts, I’m going to try to represent the Minecraft crafting tree in Neo4j. In Part 1 we looked briefly at one possible data model and then produced two CSV files ready for import into Neo4j Desktop.
In this post we’re going to do a load of those two CSVs and start exploring the graph that we get as a result.
Note: We’re going to create a database from scratch via those CSVs, then do a couple of data fixes to our database as part of this post.
If you don’t want the step-by-step, you can just directly download the minecraft.cypher file that represents the state of our database by the end of this post.
Data load
Given two CSVs structured as follows:
Items.csv – containing a single column of item names
We can do a quick load into Neo4j to see how we’re set.
First, drop the two files into the import folder then do a quick sanity check on both:
LOAD CSV WITH HEADERS FROM 'file:///Items.csv' AS row
RETURN row
LOAD CSV WITH HEADERS FROM 'file:///Recipes.csv' AS row
RETURN row
Our data model will be as we described earlier:
Nodes will be labelled with ‘Resource’ for now to cover all bases, but later we’ll maybe refine this out
name is the only property of a node so far
qty is the only property of a relationship so far
LOAD CSV WITH HEADERS FROM 'file:///Items.csv' AS row
MERGE (r: Resource { name: row.Item })
Added 187 labels, created 187 nodes, set 187 properties, completed after 193 ms.
LOAD CSV WITH HEADERS FROM 'file:///Recipes.csv' AS row
MATCH (rInput: Resource { name: row.InputItem })
MATCH (rOutput: Resource { name: row.OutputItem })
MERGE (rOutput)-[:REQUIRES { qty: toInteger(row.Qty) }]->(rInput)
Set 219 properties, created 219 relationships, completed after 330 ms.
CREATE CONSTRAINT ON (resource: Resource) ASSERT resource.name IS UNIQUE
Added 1 constraint, completed after 79 ms.
Running some queries
What all goes into a Wood Sword?
MATCH path= (r:Resource { name: 'Wood Sword' })-[:REQUIRES*]->(:Resource)
RETURN path
What’s the most convoluted item to craft?
MATCH path = (s:Resource)-[:REQUIRES*]->(e:Resource)
RETURN s, max(length(path))
ORDER BY max(length(path)) DESC, s.name DESC
LIMIT 1
Huh – really?
MATCH path= (r:Resource { name: 'Carrot on a Stick' })-[:REQUIRES*]->(:Resource)
RETURN path
Just graph the whole thing – what requires what?
MATCH path = (:Resource)-[:REQUIRES*]->(:Resource)
RETURN path
One last problem – bricks
Our import isn’t perfect – in fact just by looking around the graph interactively we can see some trouble.
From our Crafting page, we see that Bricks only require Clay Bricks to make:
But we can also make bricks directly from Clay using a furnace:
Surely that can’t be right? From the official documentation you can make Brick (as an item) from Clay in a furnace but you then combine four of those brick materials into a Bricks block.
So our source website isn’t entirely accurate, because its listing for Brick should be Bricks. We can fix up our graph for this instance by using the Clay Brick item when we mean the brick material and Brick when we mean the Brick block. We’ll then rename Brick to match the documentation and force it to be plural.
// First make the Flower Pot be constructed of Clay Brick
MATCH (pot: Resource { name: 'Flower Pot' })-[rel:REQUIRES]->(brick: Resource { name: 'Brick' })
MATCH (clayBrick: Resource { name: 'Clay Brick' })
MERGE (pot)-[:REQUIRES { qty: rel.qty }]->(clayBrick)
DELETE rel
RETURN pot, brick, clayBrick
// Now stop Bricks blocks being made of Clay and Fuel, and point those relationships over to the Clay Brick instead
MATCH (brick: Resource { name: 'Brick' })-[rel:REQUIRES]->(clay: Resource { name: 'Clay' })
MATCH (clayBrick: Resource { name: 'Clay Brick' })
MERGE (clayBrick)-[:REQUIRES { qty: rel.qty }]->(clay)
DELETE rel
RETURN brick, clay, clayBrick
I have exported the state of the database so far to this Gist – it’s pure Cypher, so just run it on a clean database in Neo4j Desktop (or whatever version you’re using).
We’ve got something that’s sort-of useful now, but we haven’t yet managed to answer the question of ‘how much Wood does it take to make a Wood Sword‘, or anything similar. We’re going to find that tricky because we’ve forgotten to import some key information from the original data source, and to tidily do that our current representation is going to cause us trouble.
Next time we’ll look at the representation problem, we’ll refactor our graph to make Recipe a first-class citizen and we’ll see what impact that has on our ability to query.
In this series of posts, I’m going to try to represent the Minecraft crafting tree in Neo4j so that we can query it and see how we might answer some basic questions like:
How much Wood does it take to make a Wooden Plank?
What are the set of recipes I need to produce a Wood Sword?
What’s the most involved recipe in the game (in terms of production steps)?
Before we go any further, I should point out that:
This isn’t necessarily a very good use-case for Neo (for reasons we’ll come to in the last Retrospective post)
We’re going to be writing some Javascript to do a bunch of the heavy-lifting towards the end
We probably should have skipped the graph database bit and just done it in memory in JS
Still – bit of fun, eh?
Setting the scene
Minecraft is a game with a crafting mechanic at its heart – to make item X, you need 3 of item Y and 1 of item Z.
The items you can craft can then be part of bigger recipes. For example, to make a Wooden Sword we need 1 Stick and 2 Wooden Planks. A Stick requires 2 Wooden Planks to make on its own, and Wooden Planks are made out of Wood which can be cut from trees in the environment.
If you imagine the steps involved in crafting a given item, you might represent it as a graph.
Each node is a resource that can be found (a raw material) or constructed from other resources
Each edge links a resource to its component parts (where it involves some recipe to make it)
In the above example, we might represent it via :REQUIRES relationships between the item being crafted and its ingredients:
We’ll need some data to work with. minecraftsavant.weebly.com has a fairly well structured table that we can work with that splits out resources into ‘things you can make at a crafting table’ and ‘things you can make in a furness’.
The markup of the site’s a bit sketchy because it’s been created using Weebly’s visual editor, but totally workable. Each craftable item has its own <table class="wsite-multicol-table"> element, and it contains two columns that we’re interested in:
The name of the item being crafted
The ingredients for the item
We’re going to have to write a bit of script to parse that into something we can turn into a graph, but nothing too crazy. And because this is a hack, we’ll just play around in the Chrome F12 developer tools. The full script is available at the end of the post.
Pulling the table contents
For each table that contains a recipe, the first cell contains the name of the item being made and the second contains its component parts. Since the formatting in different bits of the table varies, we’ll keep it simple and just use the text content of the cells.
var tables = Array.from(document.getElementsByClassName("wsite-multicol-table"));
var recipes = tables.map(t =>
{
var toReturn = {};
var item = t.rows[0].cells[0].innerText.trim();
var ingredients = t.rows[0].cells[1].innerText.split("\n");
toReturn.item = item;
toReturn.ingredientsUnparsed = ingredients.filter(i => i.length > 0).map(i => i.trim());
return toReturn;
});
We have some data quality issues here though:
The item quantity is still in the ingredient name
When multiple ingredients are required, the ingredient name has ‘and’ at the end
Item names are sometimes pluralised when listed as an ingredient when multiple are required
But not always – things like ‘Glass’ are listed as ‘3 Glass’ and not ‘3 Glasses’
Item names are pluralised when more than one of them is produced by its recipe (for example, ‘Wooden Planks’)
Item name casing is sometimes off – we want to canonicalise to title-case
Let’s fix the quantity and ‘and’ issue first, then work on canonicalising the names of items.
recipes.forEach(r => {
var extractionRegex = /^([0-9]+)? ?(.+?)( and)?$/;
// Shamelessly nicked from StackOverflow
// https://stackoverflow.com/a/4068586/677173
var fixCasing = s => s.replace(/(\w)(\w*)/g,
function(g0,g1,g2){return g1.toUpperCase() + g2.toLowerCase();});
var parsed = [];
for (var i = 0; i < r.ingredientsUnparsed.length; i++) {
var match = extractionRegex.exec(r.ingredientsUnparsed[i]);
if (match) {
parsed.push({ qty: (match[1] || 1), item: fixCasing(match[2]) });
}
}
r.ingredients = parsed;
});
Our regex matches any numeric digit string, and then captures the rest of the string (excluding any trailing ‘and’) so that the first match group is the quantity and the second the item name.
We then update each recipe with a new ingredients property, which is an array of objects with a qty and item.
Fixing up pluralisations
Pluralisation’s trickier, so we’ll go with a ‘good enough’ approach. First, which items are pluralised?
Before we spit out a CSV, let’s sanity check our data – aside from raw materials (which aren’t crafted but found), were there any typos in the data set that might screw us up?
If we tack in the ‘missing’ items to our recipe item list, we can now produce two CSVs.
// Item list
var itemList = Array.from(new Set(recipes.map(r => r.item).concat(recipes.flatMap(r => r.ingredients.map(i => i.item))))).join("\n");
// Item ingredient connections
var ingredientList = recipes.flatMap(r => r.ingredients.map(i => `${r.item},${i.qty},${i.item}`)).join("\n");
Let’s get them copied and pasted into Notepad and bash some headers on by hand. We’ll use the following headers for our Recipes.csv file:
OutputItem
Qty
InputItem
Our ‘Ingredients’ CSV is just a single column of item names, which we’ll still put a header on of ‘Item’.
We’ll need to run these same steps on the Furnace Recipes page to get the full list of craftable items. This will give two pairs of CSVs, one of the craftable items and one of the forgeable ones. We’ll just concatenate the two sets together for data loading.
Next time we’re going to load the two CSVs up into Neo4j Desktop and see what we’ve got, and start exploring issues with the data we’ve pulled in so far.