Last time we found that writing the query that told us which items to gather from the world to build any given item was between tricky and impossible to express in one Cypher query without some application code.
We outlined an algorithm that used a simulated shopping list to keep track of what we needed to run for each Recipe in the tree.
Rather than walk through the build of that here, I’ve had a stab some something poorly approximating Literate Programming and posted the code in a Gist that I’ll also embed here:
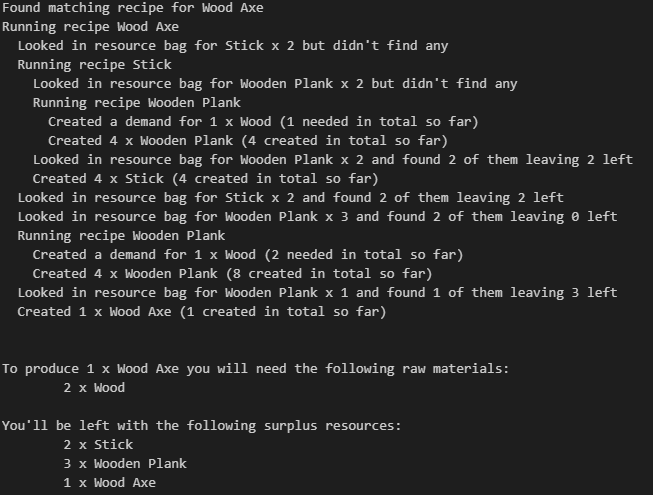
Let’s try it out then – our previous Cypher query told us that we needed 1x Wood to build a Wood Axe but that was wrong, so how does the new algorithm work out?
That’s looking tidier, we need 2x Wood.
How about producing a Carrot on a Stick?
We can see from the indentation in both shots how each Recipe ends up running other Recipes recursively until we finally hit resources that have no Recipe – raw materials.
Next steps
We’re not going to go any further with this application – we’ve tried a few things out, explored how far we can push Cypher for our use case and pulled together a quick Node app to talk to the database to do the heavy-lifting when we couldn’t manage in Cypher.
Next time we’ll do a quick retrospective on the project to wrap things up.
In this series of posts, I’m going to try to represent the Minecraft crafting tree in Neo4j so that we can query it and see how we might answer some basic questions like:
How much Wood does it take to make a Wooden Plank?
What are the set of recipes I need to produce a Wood Sword?
What’s the most involved recipe in the game (in terms of production steps)?
Before we go any further, I should point out that:
This isn’t necessarily a very good use-case for Neo (for reasons we’ll come to in the last Retrospective post)
We’re going to be writing some Javascript to do a bunch of the heavy-lifting towards the end
We probably should have skipped the graph database bit and just done it in memory in JS
Still – bit of fun, eh?
Setting the scene
Minecraft is a game with a crafting mechanic at its heart – to make item X, you need 3 of item Y and 1 of item Z.
The items you can craft can then be part of bigger recipes. For example, to make a Wooden Sword we need 1 Stick and 2 Wooden Planks. A Stick requires 2 Wooden Planks to make on its own, and Wooden Planks are made out of Wood which can be cut from trees in the environment.
If you imagine the steps involved in crafting a given item, you might represent it as a graph.
Each node is a resource that can be found (a raw material) or constructed from other resources
Each edge links a resource to its component parts (where it involves some recipe to make it)
In the above example, we might represent it via :REQUIRES relationships between the item being crafted and its ingredients:
We’ll need some data to work with. minecraftsavant.weebly.com has a fairly well structured table that we can work with that splits out resources into ‘things you can make at a crafting table’ and ‘things you can make in a furness’.
The markup of the site’s a bit sketchy because it’s been created using Weebly’s visual editor, but totally workable. Each craftable item has its own <table class="wsite-multicol-table"> element, and it contains two columns that we’re interested in:
The name of the item being crafted
The ingredients for the item
We’re going to have to write a bit of script to parse that into something we can turn into a graph, but nothing too crazy. And because this is a hack, we’ll just play around in the Chrome F12 developer tools. The full script is available at the end of the post.
Pulling the table contents
For each table that contains a recipe, the first cell contains the name of the item being made and the second contains its component parts. Since the formatting in different bits of the table varies, we’ll keep it simple and just use the text content of the cells.
var tables = Array.from(document.getElementsByClassName("wsite-multicol-table"));
var recipes = tables.map(t =>
{
var toReturn = {};
var item = t.rows[0].cells[0].innerText.trim();
var ingredients = t.rows[0].cells[1].innerText.split("\n");
toReturn.item = item;
toReturn.ingredientsUnparsed = ingredients.filter(i => i.length > 0).map(i => i.trim());
return toReturn;
});
We have some data quality issues here though:
The item quantity is still in the ingredient name
When multiple ingredients are required, the ingredient name has ‘and’ at the end
Item names are sometimes pluralised when listed as an ingredient when multiple are required
But not always – things like ‘Glass’ are listed as ‘3 Glass’ and not ‘3 Glasses’
Item names are pluralised when more than one of them is produced by its recipe (for example, ‘Wooden Planks’)
Item name casing is sometimes off – we want to canonicalise to title-case
Let’s fix the quantity and ‘and’ issue first, then work on canonicalising the names of items.
recipes.forEach(r => {
var extractionRegex = /^([0-9]+)? ?(.+?)( and)?$/;
// Shamelessly nicked from StackOverflow
// https://stackoverflow.com/a/4068586/677173
var fixCasing = s => s.replace(/(\w)(\w*)/g,
function(g0,g1,g2){return g1.toUpperCase() + g2.toLowerCase();});
var parsed = [];
for (var i = 0; i < r.ingredientsUnparsed.length; i++) {
var match = extractionRegex.exec(r.ingredientsUnparsed[i]);
if (match) {
parsed.push({ qty: (match[1] || 1), item: fixCasing(match[2]) });
}
}
r.ingredients = parsed;
});
Our regex matches any numeric digit string, and then captures the rest of the string (excluding any trailing ‘and’) so that the first match group is the quantity and the second the item name.
We then update each recipe with a new ingredients property, which is an array of objects with a qty and item.
Fixing up pluralisations
Pluralisation’s trickier, so we’ll go with a ‘good enough’ approach. First, which items are pluralised?
Before we spit out a CSV, let’s sanity check our data – aside from raw materials (which aren’t crafted but found), were there any typos in the data set that might screw us up?
If we tack in the ‘missing’ items to our recipe item list, we can now produce two CSVs.
// Item list
var itemList = Array.from(new Set(recipes.map(r => r.item).concat(recipes.flatMap(r => r.ingredients.map(i => i.item))))).join("\n");
// Item ingredient connections
var ingredientList = recipes.flatMap(r => r.ingredients.map(i => `${r.item},${i.qty},${i.item}`)).join("\n");
Let’s get them copied and pasted into Notepad and bash some headers on by hand. We’ll use the following headers for our Recipes.csv file:
OutputItem
Qty
InputItem
Our ‘Ingredients’ CSV is just a single column of item names, which we’ll still put a header on of ‘Item’.
We’ll need to run these same steps on the Furnace Recipes page to get the full list of craftable items. This will give two pairs of CSVs, one of the craftable items and one of the forgeable ones. We’ll just concatenate the two sets together for data loading.
Next time we’re going to load the two CSVs up into Neo4j Desktop and see what we’ve got, and start exploring issues with the data we’ve pulled in so far.
With a spare weekend I put together the ticker widget you can see at the top of the screen just now – iterating through my most recent GitHub activity items every few seconds.
It is, fittingly, available on GitHub for forking and customisation licensed under the BSD 3-Clause.
How it works
The GitHub API is very straightforward, and data that’s already public (such as what appears on your Public Activity tab) can be accessed without authentication and with JSONP – ideal for client-side hackery.
The widget’s architected as a couple of JS files (taking a dependency on jQuery and Handlebars for now), one which contains Handlebars precompiled templates and the other that makes the API call and renders partials befitting the type of each activity item.
Setting it up’s pretty simple – reference the JS and CSS, make sure Handlebars and jQuery are in there too and then whack a DIV somewhere on your page with id ‘gh-ticker’.
The user whose data is pulled and the interval between ticker item flips are configurable as data attributes.
The GitHub Events API
The Events API knows about a set number of event types – for each event type, there’s a Handlebars partial. When we’re wondering how to render an item we look up the relevant partial and whack it into the page.
Since that’s a fair few partials (neat for development in isolation, bad for request count overhead) those partials are precompiled using the Handlebars CLI and put into a single gh-templates.js file.
Improvements
The ticker’s very basic – it just hides or shows the items as required, without any pretty transitions. It also takes a dependency on jQuery which it needn’t, since it’s only using it for the AJAX call and element manipulation both of which are easily covered off by existing browser functionality.
Still – it can be easily styled to be fairly unobtrusive and has at least taught me a little about Handlebars.
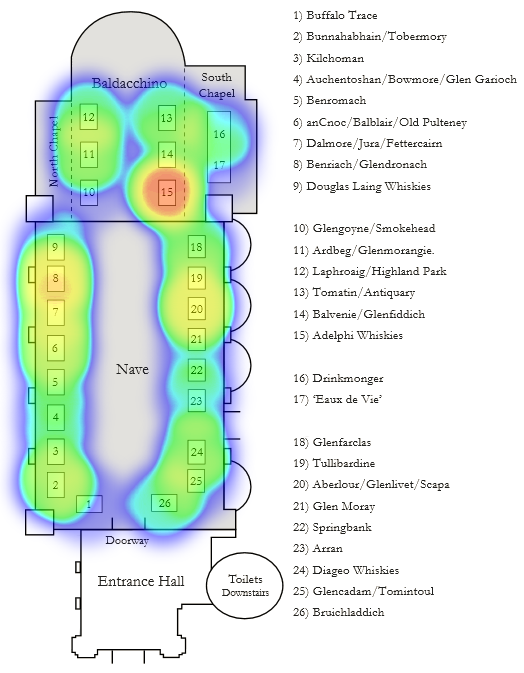
While I’m not sure if I’m going to re-run the Whisky Fringe Tasting Tracker from last year, I saw heatmap.js for the first time the other day and thought it’d be fun to make a Mansfield Traquair heatmap showing dram-sampling by stand. Here’s the result:
The 675 samplings recorded by www.wf2012.co.uk over the 2012 Whisky Fringe
Not bad for a first attempt. That’s 675 samplings tracked by stand – of course, some stands had appreciably more drams to sample than others but there were definite hotspots. Given that we have opinion data too, we can also plot the hotspots of most-liked drams:
Positive opinions recorded at each stand during the 2012 Whisky Fringe – broadly similar but with some interesting detail
If I do run it again this year it’d be great to get heatmap.js combined with the above floorplan image and Pusher for some real-time updates…
I always loved Ceefax as a kid, and in particular (for reasons that probably indicate some manner of mental deficiency) Pages From Ceefax, the small non-navigable subset that was broadcast after-hours accompanied by a variety of big-band and easy listening music. And with a spare bank holiday weekend at my disposal and a girlfriend who is more accepting of my eccentricities than is necessarily prudent, I put together an HTML5 canvas + Javascript version that pulls in RSS feeds from the BBC news website and renders them in a hand-made sprite font:
Click image for project page – requires HTML5 canvas support
Two sprite fonts (one for character data and one for the graphics blocks from the header section) are combined with feeds from the BBC periodically downloaded by a cron job. Three feeds are in use in the above sample – the Top Stories, Sport and Business feeds. Each of these map to a single page (signified by the Pxxx number at the top of the view).
These are then split down into subpages so that both headline and byline are rendered together. For a given page there will be one or more subpages that contain the actual content – these are cycled between on a 15 second interval, and when all of the subpages of a given page have been shown the next page is slotted into place.